Watchdog chain
In optiMEAS devices, a strong focus is placed on fail-safety, high availability and reliability in operation. A key element here is a continuous watchdog chain from the hardware to the software components.
Basic principle
The watchdog chain in the optiMEAS devices is made up of a combination of hardware and software components that together form a monitoring line. In this line, the functionality of each individual component is continuously monitored. If a component fails, measures are automatically initiated to ensure smooth operation, including the targeted restart of individual processes, the complete software restart of the Linux system and the selective shutdown and subsequent restart of individual hardware components or even the entire system.
The watchdog chain is shown schematically in the following figure.

The individual monitoring levels
The lowest level is the hardware watchdog (power controller). This is a microcontroller that is able to specifically de-energize and restart all other hardware components (main processor with Linux system, modem, etc.). It itself has an internal watchdog that restarts it in the event of an error.
This hardware watchdog expects a cyclical sign of life from the level above it, the device manager. The device manager is a central software component that sends a sign of life to the hardware watchdog via the I2C bus. It monitors all application-specific software processes (apps) and is itself started and monitored by the Linux process "systemd". In the event of an error, systemd attempts to restart the device manager up to five times before a complete software restart is performed.
All application-specific software processes (apps) form the level above the Device Manager. The DeviceManager monitors the apps (e.g. the smartCORE) via a software watchdog. The list of apps to be monitored is already defined in the system configuration so that the DeviceManager can already monitor the start of the processes. This also covers cases in which the process crashes during startup. If there is no watchdog signal, the process is specifically terminated and restarted. The process restarts are counted and a reboot occurs if certain limits are exceeded. Stable operation over a longer period resets the counter.
What happens in the event of an error
Let's take a look at what happens when individual components fail: If an app "crashes", it does not send a sign of life to the device manager. The device manager then restarts the app and counts the restarts of the app over time. If the problem cannot be solved by restarting the app, i.e. if the components fail repeatedly, the entire system is restarted.
If the device manager itself crashes, the Linux systemd process takes over first and restarts the device manager up to five times. If stable operation is still not achieved, the entire Linux system is restarted.
If the device manager and systemd fail, the watchdog signal to the hardware watchdog remains off. This would then restart the entire system via a power cycle.
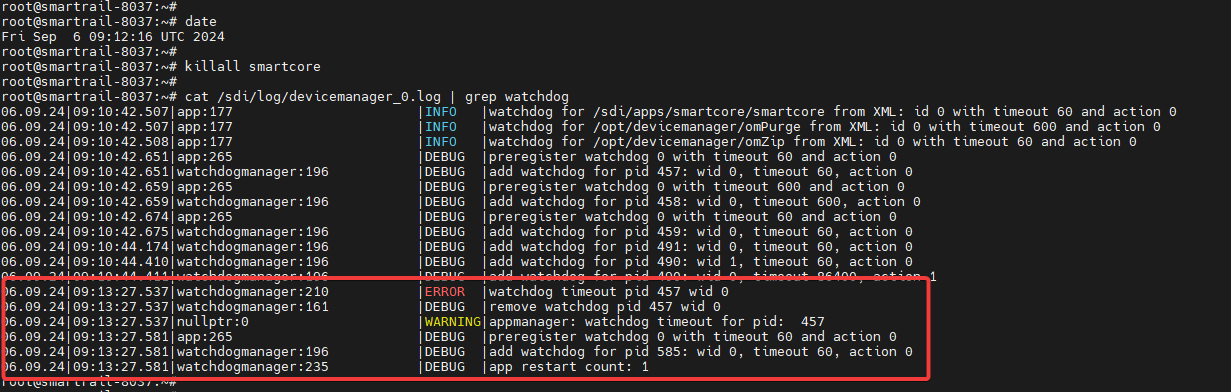
Simple test of the system
It is not recommended to intervene manually in the system. If the experienced user nevertheless wishes to test the system, the following procedure is recommended. After authentication and dialing into the system, a monitored process is terminated via the Linux console, e.g. with
killall smartcore
After a short time, the device manager will recognize the absence of the sign of life and thus the failure of the process. The process is then restarted by the device manager.
The absence of a sign of life and the restart of the process are recorded in the log files of the device manager. A glance at the log file reveals the process.